Configuration: Data Pipeline
Overview
The OCS data pipeline is built on Apache Nifi and consists of two core data processing functions:
- The export of the OCS real-time database wallet storage into timestamped point-in-time snapshots of OCS data in the reporting database.
- The stream processing of OCS EDRs to extract debit and credit activities, storing changes to wallet buckets as timestamped records in the reporting database.
Apache Nifi itself isn’t responsible for managing the size of the PostgreSQL database. Nifi ingests data, but does not remove it.
Pre-Requisites
Prior to configuring Apache Nifi for OCS data processing, ensure that it is installed. OCS specific installation instructions are included in this documentation.
Web Designer Access
Once installed, Apache Nifi will be accessible on the reporting server at the URL: https://n2ocs-reporting-server/nifi, or alternatively if Nifi is not proxied, at http://n2ocs-reporting-server:8080/nifi. The initial Nifi GUI is a blank canvas in which data pipelines can be created and enabled, analysed and monitored.
Into this blank canvas, the OCS-specific data pipeline configuration be loaded as described next.
Real-Time Database Snapshots
To enable real-time database snapshots of wallet from the OCS database, import into Apache Nifi the file Read_All_OCS_Accounts_into_Postgres.xml. This file will be versioned - e.g. Read_All_OCS_Accounts_into_Postgres_v1.0.xml. This file will be available at /opt/nsquared/ocs/etc/nifi on any machine with the N-Squared OCS installed, or the latest version can be requested via an email to support@nsquared.nz.
To import this file, use the “Upload Template” button in the Operate box of the Nifi GUI:
Once uploaded, the template (and all templates) can be accessed using the templates menu item, available through the hamburger bar of Nifi. Note that if this same versioned template is already uploaded, the upload fails and for this reason the version number of the template is included in name of the template.
Once available, use the template button to include the template into the Nifi data pipeline:
This template defines the full process for extracting data from the OCS real-time database, transforming the data, and inserting into the PostgreSQL database.
Configuration
To configure the real-time database snapshot process, right click the “Read All OCS Accounts into Postgres” node, and choose the variables context menu item. The variable list will be displayed to the variables dialog box:
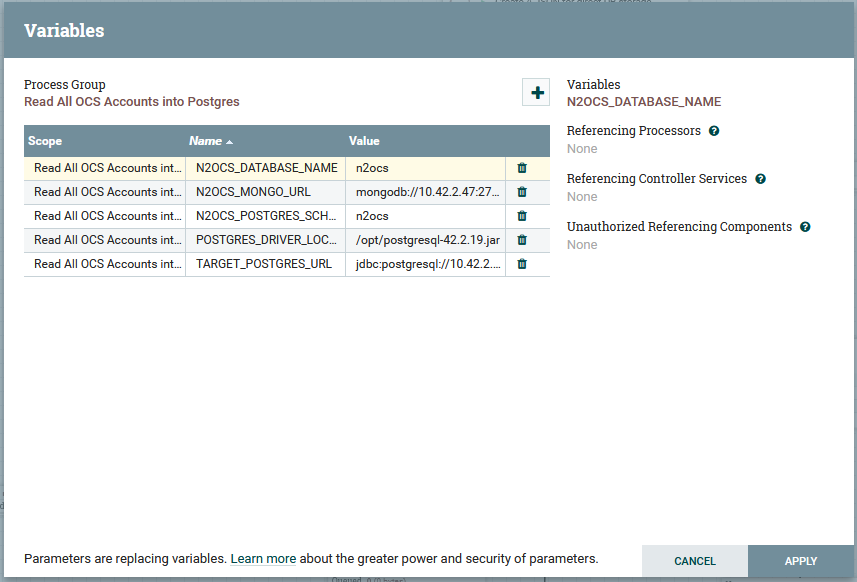
The following variables need configuration in this dialog box:
| Variable | Description | Default Value |
|---|---|---|
N2OCS_DATABASE_NAME |
The name of the real time OCS database in the Mongo server. | n2ocs |
N2OCS_POSTGRES_SCHEMA_NAME |
The name of the PostgreSQL schema that holds the reporting database table n2ocs_account_snapshot |
n2ocs |
N2OCS_MONGO_URL |
The URL of the real-time OCS Mongo server. | - |
POSTGRES_DRIVER_LOCATION |
The file location on the Apache Nifi server where the postgres JDBC driver can be found. This will need to be downloaded onto the server as part of installation, e.g. from https://jdbc.postgresql.org/ | /opt/postgresql-42.2.19.jar |
TARGET_POSTGRES_URL |
The JDBC URL where the system can find the reporting database schema (as configured in N2OCS_POSTGRES_SCHEMA_NAME) |
- |
In addition to the direct configuration in the variables list, the following configuration may also be altered.
Extraction Scheduling
The extract of wallet data from the real-time database is scheduled to occur once per day at midnight. This can be changed by editing the “Read all OCS Accounts from Mongo” node within the “Read All OCS Accounts into Postgres” template node.
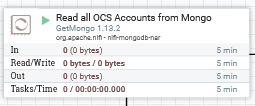
In the node’s scheduling tab, the schedule is set (by default to 0 0 0 * *, which is daily at midnight):
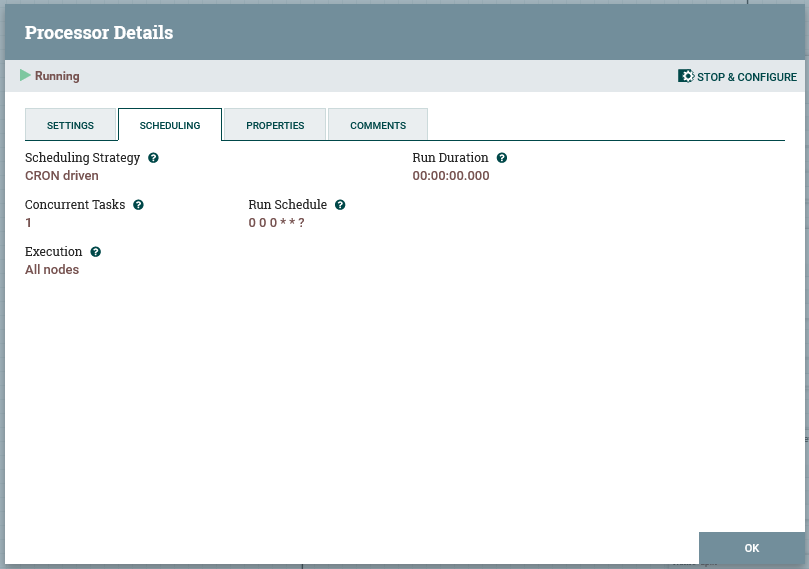
The format of the schedule is the standard Unix CRON format, and can be run as frequently as desired, however note that:
- Extracting all wallet data from the Mongo database is not a zero-cost operation. Be sure to not impact real-time traffic with a frequency that is too high.
- Storage requirements for the PostgreSQL database must be sufficient to store all wallet data for the time period required for reporting data retention.
PostgreSQL Database Password
Unfortunately the PostgreSQL database password cannot be configured in the variables screen shown previously. Instead, the username and password to access PostgreSQL is configured in the services used by the “Save to Postgres” node:
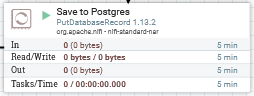
Edit the “Save to Postgres” node’s configuration, and access the “Database Connection Pooling Service” property. This is a service called “N2OCS Postgres DB”:
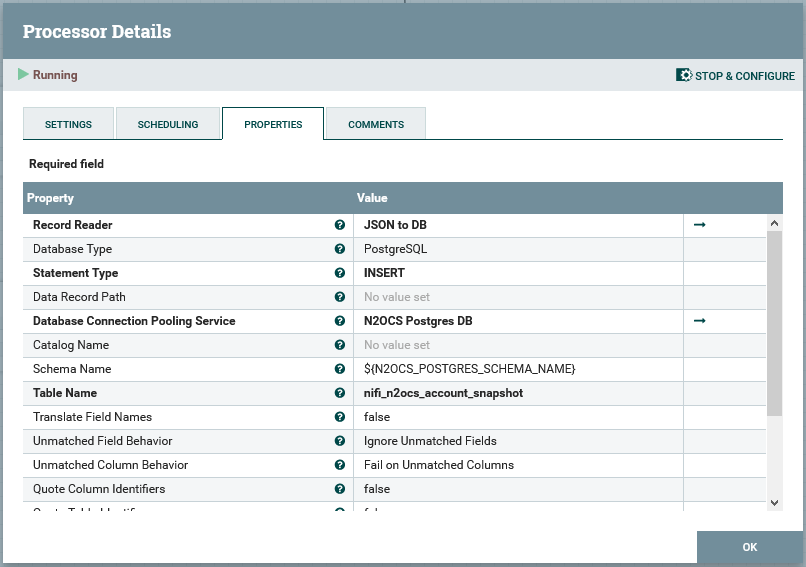
Load from here the “N2OCS Postgres DB” service, and configure the Database User and Password configuration options:
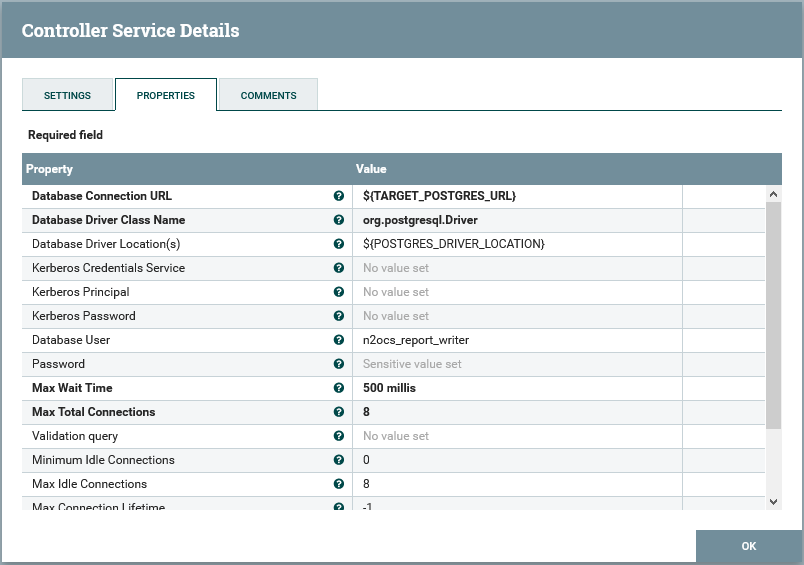
The Password must be set after import, as sensitive values are not imported from template XML files.
Enabling the Data Pipeline
Each N2OCS data pipeline template is independent and can be enabled and disabled separately. Ensure, once all configuration is applied, that the pipeline process is started:
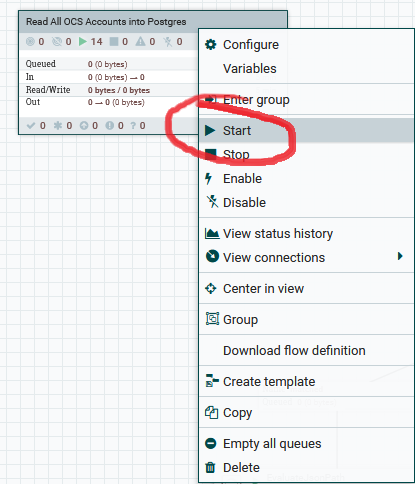
It is recommended that the data pipeline is tested by setting the schedule for the “Read all OCS Accounts from Mongo” to execute immediately, and check the data inserted into the reporting database.
Verifying Exports
To verify the exported snapshot(s) from the Mongo database, log in to the reporting database as either a report reader or writer, and run the following SQL:
n2reporting=# select nifi_insert_timestamp, count(*) from n2ocs.nifi_n2ocs_account_snapshot group by nifi_insert_timestamp;
Output should be similar to:
nifi_insert_timestamp | count
------------------------+-------
2021-03-17 00:00:00+12 | 159
2021-03-15 00:00:00+12 | 159
2021-03-16 00:00:00+12 | 159
2021-03-14 00:00:00+12 | 186
where each day the export is run, the wallet count matches the total number of buckets + wallets without buckets in the system.